
Introduction
72% of organizations have integrated AI into at least one business function, according to McKinsey's 2024 Global Survey — and Gartner predicts AI applications will drive 50% of cybersecurity incident response efforts by 2028. Deployment is accelerating. Security maturity is not.
The real problem is scope. AI applications expose a fundamentally different attack surface than traditional software — training data, model weights, prompt inputs, agent permissions, and runtime behavior are all exploitable vectors.
Standard security tools were built for deterministic code. They weren't designed to catch prompt injection, data poisoning, or model theft.
This guide covers:
- What makes AI applications uniquely vulnerable
- Which security controls actually reduce risk
- Where most teams go wrong
- How to build a security program that keeps pace with the systems you're deploying
TL;DR
- AI introduces unique attack vectors — prompt injection, data poisoning, model inversion, and model theft — that SAST, DAST, and WAFs cannot detect
- Securing AI requires coverage across development, testing, and runtime — not just a pre-launch checkpoint
- The OWASP LLM Top 10 (2025) and NIST AI RMF are the most practical starting points for governance and threat taxonomy
- Automated scanners miss business logic flaws and chained vulnerabilities in AI systems — manual validation is non-negotiable
- Least-privilege access, behavioral monitoring, and adversarial testing deliver the highest immediate risk reduction
What Is AI Application Security?
AI application security is the set of policies, controls, and technologies protecting AI-powered systems — including their training data, model weights, input/output pipelines, and runtime behavior — from unauthorized access and manipulation.
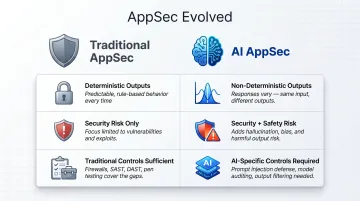
The definition sounds familiar. The problem underneath it is not. AI AppSec diverges from traditional application security in three specific ways:
- Non-determinism: Traditional AppSec addresses deterministic code in static systems. AI systems produce different outputs from identical inputs, and new failure modes can emerge after deployment without any code change.
- Dual risk dimensions: AI AppSec must address both security failures (attackers exfiltrating data or hijacking model behavior) and safety failures (the model producing harmful, biased, or unauthorized outputs). A compromised model can simultaneously leak data and produce dangerous outputs — a compounding failure that has no clean parallel in conventional software.
- Insufficient traditional controls: ENISA's Multilayer Framework for Good Cybersecurity Practices for AI explicitly structures its guidance to show that traditional cybersecurity forms only the base layer — AI-specific controls are a distinct, additional requirement, not an extension of existing tools.
NIST AI 600-1 identifies 12 risk categories unique to generative AI, including confabulation, data privacy violations, and information integrity threats. None of these fall within the scope of traditional application security. The frameworks that address them exist — but most organizations haven't mapped their AI systems against them yet.
Core Threats Targeting AI Applications
Prompt Injection
Prompt injection occurs when malicious inputs override system instructions, causing the AI to bypass security controls, leak sensitive data, or execute unauthorized commands.
Two variants exist:
- Direct injection: The user's own input manipulates model behavior — intentionally or otherwise
- Indirect injection: An attacker plants hidden instructions in external data sources the model processes (documents, emails, web pages, or outputs from compromised peer agents in multi-agent systems)
The OWASP LLM Top 10 2025 ranks prompt injection as the #1 risk for LLM applications. Automatic detection is also unreliable — regex blocklists fail against paraphrased attacks, and the attack surface expands every time the model gains access to new external data.
Data and Model Supply Chain Poisoning
Attackers who gain access to training pipelines inject manipulated data that corrupts model behavior, introduces hidden backdoors, or biases outputs — all before the model ever reaches production. Because the compromise happens upstream, standard runtime defenses don't catch it.
The scale required is lower than most teams assume. Research from Anthropic, the UK AISI, and the Alan Turing Institute demonstrated that as few as 250 malicious documents can backdoor an LLM, regardless of model size. Separately, SEI/CMU documented that altering just 0.1% of training data — 50 images out of 50,000 — can constitute a successful poisoning attack.

Model Theft, Inference Attacks, and Privacy Leakage
Repeated API queries can be used to clone proprietary models or reconstruct confidential records from outputs. The business impact is direct: stolen model IP, eroded competitive advantage, and exposure of sensitive training data.
Privacy leakage compounds the risk further. Research by Carlini et al. demonstrated that training data extraction attacks on GPT-2 recovered hundreds of verbatim text sequences — names, phone numbers, email addresses, and 128-bit UUIDs the model had memorized and could reproduce through targeted queries. Membership inference attacks take this further still, revealing whether specific records appeared in training data at all — a direct compliance exposure for any model trained on regulated or sensitive data.
The OWASP LLM Top 10 as Your Threat Taxonomy
Beyond the threats above, the OWASP LLM Top 10 2025 is the most widely adopted framework for categorizing LLM-specific risks. Use it to map your deployments against a complete threat taxonomy — not just the headline items. Additional categories it covers include:
- Insecure output handling
- Excessive agency
- System prompt leakage
- Vector and embedding weaknesses
- Unbounded consumption
AI Application Security Best Practices
Effective AI security requires layered controls across three dimensions: who can access the system, what the system can do at runtime, and how inputs and outputs are validated.
Foundational Access and Identity Controls
Every AI agent, API endpoint, and service account should operate with permissions scoped only to the specific data and actions it requires for that task — nothing more.
The cost of getting this wrong is measurable. Industry data shows over-privileged AI systems drive 4.5× higher security incident rates — 76% vs. 17% — and 70% of organizations currently grant AI agents higher access than required. A single compromised agent with elevated privileges becomes a pivot point across multiple systems.
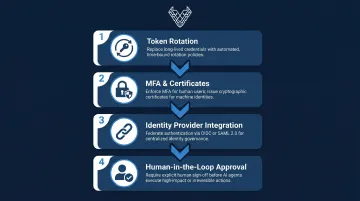
Practical controls include:
- Replace long-lived credentials with automated token rotation policies
- Implement MFA for human users and cryptographic certificates for machine identities
- Connect AI systems to enterprise identity providers via OIDC or SAML 2.0 for centralized policy enforcement
- Require human-in-the-loop approval for any high-impact agent actions
Runtime Monitoring and Behavioral Analytics
Behavioral anomalies are often the first — and only — signal that an AI agent has been compromised. Without a documented baseline, there's no reference point to distinguish normal operation from active manipulation.
Establish behavioral baselines before production. Specifically monitor for:
- Unusual data access volumes or frequency spikes
- API calls to unexpected external endpoints
- Outputs containing sensitive data patterns (PII, credentials, internal record formats)
- Geographic or time-based access anomalies
Integrate AI application logs with your SIEM for unified visibility. Use SOAR workflows to automate initial response actions — suspending agent access, for example — when critical anomalies are detected.
The IBM Cost of a Data Breach Report 2024 found that organizations using AI and automation in prevention workflows reduced average breach costs by $2.2 million. Faster detection directly reduces your breach cost exposure.
Input Validation and Output Filtering
Regex-based input filtering fails against prompt injection. Attackers routinely bypass blocklists through paraphrasing, encoding, or instruction fragmentation.
Implement semantic input validation using lightweight classifiers that detect paraphrased jailbreak attempts and injection markers before inputs reach the model. The PromptGuard framework, published in Scientific Reports, achieved 97.5% detection accuracy against direct injection and 94.3% against indirect injection across GPT-4o, Claude 3.5, and Llama 3 — using a four-layer approach combining intent classification with semantic output validation.
Even at those accuracy rates, a 2.5–5.7% miss rate is meaningful at scale. Pair classifier-based input filtering with:
- Output filtering that scans AI-generated responses for PII, credentials, and confidential record patterns before returning results to users
- Rate limiting at the API gateway layer to limit model extraction attempts
- Schema validation to reject malformed or unexpected output structures
Securing AI Across the Development Lifecycle
Shift Left — Starting at the Training Pipeline
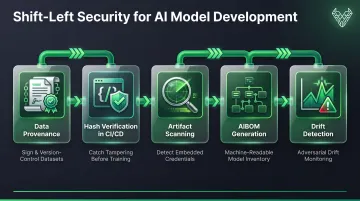
Security embedded at the start of model development costs a fraction of post-deployment remediation. The most critical shift-left controls for AI are:
- Validate training data provenance — digitally sign and version-control every dataset entering the pipeline
- Verify data hashes in CI/CD — catch tampering before training begins
- Scan model artifacts for embedded credentials and known-malicious components
- Generate a model SBOM (AIBOM) — the OWASP AIBOM project provides an open-source generator that produces machine-readable inventories of model origin, component versions, and upstream dependencies
- Deploy concept-drift detectors on new data ingests — adversarial drift designed to mimic real drift can fool standard detectors, so purpose-built adversarial drift detection is essential for high-stakes models
Adversarial Testing Before Deployment
Automated vulnerability scanners cannot replicate the attack chains, business logic abuses, and chained privilege escalations that human testers identify in AI systems. NIST AI 600-1 recommends combining automated tools with diverse human red teams, noting that non-expert testers identify failure modes that both expert and automated systems miss.
Manual AI/LLM security assessments — like those Vynox Security conducts — surface prompt injection paths, agent permission chains, and model-level behavior flaws that tool-only scans miss. Automated scanners produce a checklist. Manual adversarial testing produces an attack chain.
Incident Response Playbooks Tailored to AI
Pre-deployment testing reduces risk, but no system is immune. Generic incident response plans don't account for AI-specific failure modes — these two playbooks should be ready before you need them:
Prompt injection response:
- Trace every user query through logs to reconstruct the injection chain
- Rotate API keys and suspend affected agent access
- Patch the input validation layer and retest before restoring service
Data poisoning response:
- Isolate the build pipeline immediately to prevent further model training on compromised data
- Identify the contamination window using signed data manifests and hash verification
- Redeploy from a clean model snapshot using a versioned model registry
A versioned model registry with rollback to known-good states is the difference between a confirmed incident resolved in minutes and one that drags on for weeks.
Common AI Security Mistakes to Avoid
Most AI security failures trace back to three repeatable mistakes — ones that traditional security tooling isn't designed to catch.
Treating Automated Scan Results as Full Coverage
SAST, DAST, and dependency scanners don't test prompt injection paths, agent permission chains, or model-level behavior. Organizations that rely solely on these tools carry false confidence: the attack surfaces that matter most for AI systems fall entirely outside what those scans measure.
Granting AI Agents Excessive Permissions at Deployment
Teams routinely assign broad permissions to simplify integration, intending to restrict them later. Those restrictions rarely happen. The result is a deployed agent with database admin access when read-only was all it needed — one compromised session away from a cross-system data breach.
Skipping Behavioral Baselining Before Production
Without documented normal behavior established at launch, security teams have no reference point. Subtle manipulation and slow-burn data exfiltration look indistinguishable from expected operation — until real damage has already occurred and the trail has gone cold.
Frequently Asked Questions
Do I need AI security?
Any organization deploying AI applications — chatbots, decision-support tools, LLM-powered workflows — faces attack surfaces that traditional security controls don't cover. Prompt injection and data poisoning require minimal attacker effort to execute against poorly secured deployments. If you're running AI in production, you need AI-specific controls.
How is AI used in application security?
AI enhances security operations through behavioral analytics, anomaly detection, automated threat response, and accelerated vulnerability analysis. AI also introduces new risks in development — AI-generated code can embed vulnerabilities that require the same scrutiny as any other code. Organizations need to manage both sides of that equation.
How do I ensure my AI is secure?
Core controls include: least-privilege access for AI agents, cryptographically signed training data, semantic input filtering, output scanning, and SIEM-integrated AI logging. Automated tools establish a baseline — manual adversarial testing is what closes the gaps they miss.
What are the applications of AI in auditing?
AI handles continuous transaction monitoring, anomaly detection, automated log analysis, and compliance reporting in auditing contexts. The tools themselves must be secured against data poisoning — a compromised audit system produces results you can't rely on.
What is an example of an AI application?
Examples include LLM-powered customer service chatbots, fraud detection systems in banking, clinical decision-support tools, and AI code assistants. Each handles sensitive data in contexts where a security failure carries real business and regulatory consequences.


