
Introduction
Most teams assume they know what AI penetration testing means. Few agree on the definition — and that disagreement leaves real attack surfaces unchecked.
The term covers two distinct activities: using AI-powered tools to automate and accelerate security assessments, and testing AI systems themselves (LLMs, ML models, RAG pipelines) for vulnerabilities unique to how those systems work. Conflating these two leads to scoped engagements that miss entire attack surfaces.
For security teams at startups, SaaS providers, and mature organizations, the stakes are concrete. The OWASP Top 10 for LLM Applications v2025 documents risks including prompt injection, data poisoning, and sensitive information disclosure — none of which traditional scanners catch.
The assumption that deploying AI-assisted testing tools equals complete security coverage is one of the most common and costly mistakes teams make.
What follows is a ground-level look at how AI pen testing works — and where human judgment remains the deciding factor between a checkbox exercise and a test that actually finds what matters.
TL;DR
- AI pen testing covers two distinct things: finding AI-specific vulnerabilities in AI systems, and using AI tooling to scale traditional security assessments
- Standard vulnerability scanners miss AI-specific risks like prompt injection, data poisoning, model inversion, and data leakage
- The testing lifecycle follows familiar phases — scoping through reporting — but requires AI-aware techniques and frameworks like OWASP LLM Top 10 and MITRE ATLAS
- Automation scales coverage but cannot replace human judgment for chaining exploits, assessing business impact, or identifying logic-layer flaws
- AI systems change continuously; one-time testing is insufficient
What Is AI Penetration Testing?
AI penetration testing covers two distinct things: finding exploitable security weaknesses in AI and ML systems, and using AI-assisted tools to automate traditional security testing across infrastructure and applications. Most confusion in this space comes from conflating the two.
The goal is to confirm which vulnerabilities are actually exploitable, demonstrate real-world impact, and produce remediation guidance that engineering and security teams can act on — not a list of theoretical weaknesses.
How It Differs from Related Disciplines
These three activities are often used interchangeably. They shouldn't be:
| Discipline | Focus | Time Horizon | Output |
|---|---|---|---|
| AI Penetration Testing | Exploitable security flaws in AI systems and pipelines | Time-bounded engagement | Validated findings with proof of concept |
| AI Red Teaming | Unsafe behaviors, misuse, failure modes across the model lifecycle | Extended, iterative | Behavioral risk assessment |
| Model Evaluation | Performance, safety metrics, bias, jailbreak resistance | Ongoing, metric-driven | Measurement data under governance frameworks |
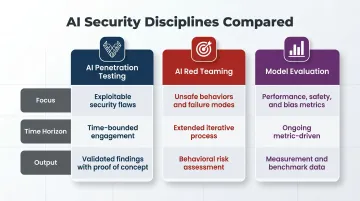
Palo Alto Networks describes AI red teaming as broader and behavior-focused, while pen testing targets specific exploitable weaknesses within defined scope. Conflating them means behavioral risks slip through pen test scopes, and exploitable technical flaws get lost in red team behavioral assessments.
How AI Penetration Testing Works
The process follows the same lifecycle as traditional pen testing — scoping, discovery, exploitation simulation, validation, reporting — but each phase requires AI-aware tooling and AI-specific threat models. An engagement targeting an LLM-integrated application looks structurally different from one targeting a web application or cloud network.
Step 1: Scoping and Threat Modeling
Scoping for AI systems goes beyond network boundaries. Teams must account for:
- All AI assets: models, embedding stores, vector databases, fine-tuned variants, third-party LLM APIs
- Abuse scenarios grounded in how the system is actually used, not just how it was designed
- Whether the organization uses a third-party API (such as OpenAI or Azure OpenAI) versus self-hosting an open-source model — this materially changes the attack surface and what's testable
A self-hosted fine-tuned model exposes the model weights, training pipeline, and infrastructure to direct assessment. A third-party API integration shifts the scope toward prompt handling, output validation, and data flowing through the integration. Rules of engagement differ accordingly.
MITRE ATLAS and the OWASP LLM Top 10 both serve as inputs at this stage — ATLAS for mapping adversarial tactics to test hypotheses, OWASP for ensuring risk categories are covered in scope definition.
Step 2: Discovery and Adversarial Reconnaissance
AI-assisted tools map the attack surface faster than manual methods alone. In this phase, testers:
- Enumerate API endpoints, model input/output behavior, and integration touchpoints
- Probe for information leakage through system prompts or model responses
- Identify over-permissioned tool integrations (a specific concern under OWASP LLM06 Excessive Agency)
- Test model behavior under adversarial prompts to surface safety-control weaknesses before exploitation begins
Step 3: Exploitation Simulation, Validation, and Reporting
Testers craft adversarial inputs — prompt injections, malicious payloads, chained attack sequences — to demonstrate real exploitability rather than theoretical risk. Before a finding is classified as a validated vulnerability, human testers confirm it against actual exposure, permissions, and data access in the target environment — not just theoretical attack paths.
Human judgment is essential here. Determining whether a finding propagates through connected systems or has bounded impact requires understanding the business context. Automated tools surface candidates; humans assess whether they matter.
The final report should include:
- Severity ratings mapped to business impact, not just CVSS scores
- Proof-of-concept evidence for every confirmed finding
- Specific remediation steps with enough context for engineering teams to act
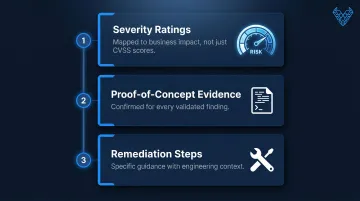
A report that distinguishes confirmed exploits from theoretical risks gives engineering teams a clear prioritization order — and makes remediation faster.
Key AI-Specific Vulnerabilities and Testing Techniques
Standard vulnerability scanners match systems against known flaw databases. The vulnerabilities below don't appear in those databases — they require active adversarial testing to uncover.
Prompt Injection and Safety-Control Bypass
Carefully crafted inputs that steer models away from intended behavior, override system instructions, or extract restricted content. Even well-aligned models can be manipulated through:
- Indirect prompts embedded in retrieved content (a significant risk in RAG architectures)
- Multi-step interactions that gradually shift model behavior
- Instruction conflicts between system prompts and user inputs
OWASP LLM01 identifies this as the leading LLM application risk in the 2025 list.
Data Poisoning
Malicious or manipulated data that enters training or fine-tuning pipelines, systematically altering model behavior, introducing hidden triggers, or degrading performance in targeted scenarios. Testers assess how data is collected, validated, and monitored — not just whether the model produces correct outputs today.
Model Inversion and Extraction
Repeated API queries can reverse-engineer proprietary models or extract sensitive training data — particularly relevant for fine-tuned models that encode domain expertise or personally identifiable information. Practical defenses include rate limiting, output monitoring, and access controls. The real question isn't whether those defenses exist on paper — it's whether they hold under adversarial query patterns.
Inference-Time Data Leakage
Models can reveal information embedded in prompts, conversation history, retrieval systems, or training artifacts without any obvious system failure. OWASP LLM02 (Sensitive Information Disclosure) and the European Data Protection Board's guidance on LLM privacy risks both document how this manifests in production — and why it's directly relevant to GDPR compliance.
Frameworks That Structure the Methodology
Each of the vulnerability categories above maps to established adversarial taxonomies. Three frameworks guide how they're scoped, tested, and reported:
- OWASP LLM Top 10 (2025): Application-layer AI risks with concrete categories for finding classification and reporting
- MITRE ATLAS: Adversarial tactics and techniques drawn from real-world ML incidents, including documented attacks against government infrastructure systems
- NIST AI RMF: Governance functions (Govern, Map, Measure, Manage) that align findings to leadership priorities and audit requirements
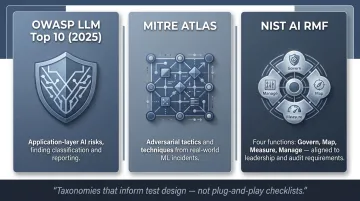
These are taxonomies that inform test design. They are not plug-and-play checklists, and treating them as such produces assessments that check boxes without identifying real risk.
When AI Automation Alone Falls Short
Automated adversarial prompt tools are genuinely useful — they run high-volume test cases, fuzz inputs at scale, and surface common failure patterns faster than manual testing. But they have predictable blind spots that matter.
What Automation Consistently Misses
- Exploits behaviors that violate business rules the tool has no context for — classic business logic flaws no scanner can reason about
- Misses how low-risk findings chain together into critical exploits when sequenced the way a real attacker would
- Skips access control failures that only surface when tested against actual user roles and real data access patterns
Vynox Security was founded specifically because this pattern — critical attack chains and business logic flaws missed by automated tools — was appearing consistently across organizations that believed their automated scans had them covered. Their manual-first, threat-led methodology is built around asking one question: if this system were attacked in the real world, what would actually break?
The Compliance Dimension
That same gap — automation missing what a real attacker would do — is exactly what compliance auditors flag. Organizations pursuing SOC 2, ISO 27001, or GDPR need human-validated evidence: findings confirmed against real exposure, with documented remediation and retest results. Automated-only reports typically fail SOC 2 Type II requirements under CC4.1 because they don't demonstrate control effectiveness against adversarial behavior.
ISO/IEC 42001, the emerging AI management system standard, requires that AI risks be governed appropriately to risk level. That governance expectation means organizations need human-validated testing for high-risk AI deployments. Vynox structures its reports for both technical and compliance audiences, mapped to OWASP, ISO 27001, and GDPR — so findings hold up when auditors ask for them.
Continuous Testing as a Requirement, Not a Best Practice
The OWASP AI Testing Guide v1 positions AI security validation as a lifecycle standard rather than a point-in-time exercise. AI systems change continuously — through model retraining, prompt updates, RAG data refreshes, and new tool integrations. A test that passes today can be invalidated by next week's model update.
Practical triggers for re-testing:
- Significant model or fine-tuning updates
- Changes to prompt templates or system instructions
- New API integrations or tool capabilities
- Expanded user access or data exposure
- Major compliance review cycles
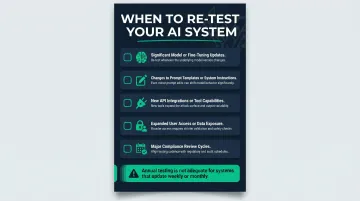
Annual testing is not adequate for systems that update weekly or monthly.
Frequently Asked Questions
How does AI penetration testing work?
It follows the standard pen testing lifecycle — scoping, discovery, exploitation simulation, validation, reporting — using AI-aware tools and adversarial techniques that target model behavior, data pipelines, and integrations. Human validation is required to distinguish genuinely exploitable risks from theoretical findings that don't reflect real-world exposure.
Can AI perform penetration testing?
Yes — AI-assisted tools can automate adversarial prompt generation, input fuzzing, and attack surface mapping at scale. They cannot replicate human judgment for chaining exploits, assessing business impact, or identifying context-dependent logic flaws that require understanding how a system is intended to work.
Which AI tools are used for penetration testing?
Commonly used tools include Garak (LLM vulnerability scanner), Promptfoo (prompt testing with red teaming features), DeepTeam (adversarial LLM framework), and Microsoft Counterfit (adversarial ML assessment). The right toolset depends on your target — LLM app, API layer, ML pipeline, or cloud infrastructure — and should align with OWASP LLM Top 10 and MITRE ATLAS for structured coverage.
Is AI taking over penetration testing?
AI is augmenting it — accelerating discovery, scaling coverage, and enabling continuous regression testing. Human expertise remains essential for the judgment-intensive phases: determining real-world exploitability, assessing blast radius, prioritizing remediation, and identifying novel attack paths that tools cannot enumerate.
Is penetration testing legal?
Yes, when conducted with explicit written authorization under a clearly defined scope. Unauthorized testing violates the Computer Fraud and Abuse Act (18 U.S.C. § 1030) — the DOJ's 2022 CFAA policy protects good-faith security research only when authorization is documented before testing begins.
What's the difference between AI penetration testing and AI red teaming?
AI pen testing validates whether specific vulnerabilities are exploitable at a point in time, within a defined scope. AI red teaming is broader — it simulates realistic attacker behavior over an extended period to test detection, response, and operational readiness, not just whether individual technical controls hold.


