
HackerOne's research found that 84% of organizations experienced at least one AI-related attack or vulnerability in the past 12 months. Yet only 66% formally test the majority of their AI systems. That gap is where attackers operate.
This post covers three things: what AI red teaming actually means, why it demands a fundamentally different approach than traditional pen testing, and how to implement it—whether you're a startup shipping your first LLM feature or a mature org scaling agentic AI products.
AI systems introduce an attack surface that standard pen tests weren't designed to evaluate: natural language inputs, probabilistic model behavior, retrieval pipelines, and tool integrations. Testing that surface requires a different methodology entirely.
TL;DR
- AI red teaming is adversarial testing of your AI system's model behavior, prompts, integrations, and outputs—not just your infrastructure
- Traditional pen testing targets deterministic systems; AI's probabilistic nature makes one-time testing insufficient
- The biggest risks for most organizations are application-level: prompt injection, RAG data leakage, and agentic tool misuse
- Real incidents (Samsung, Air Canada, Chevrolet) show the business cost of skipping this
- Five-step implementation: threat model, team assembly, scoped testing, severity scoring, SDLC integration
What Is AI Red Teaming?
AI red teaming is a structured, adversarial testing process where a team of experts probes an AI system—its model behavior, inputs, outputs, integrations, and data pipelines—to find vulnerabilities before real-world attackers do. It's not a product review or a compliance audit. It's active exploitation simulation, applied to AI.
The US Executive Order 14110 defines it precisely: "a structured testing effort to find flaws and vulnerabilities in an AI system, often in a controlled environment and in collaboration with developers of AI."
Two Distinct Targets Most Guides Conflate
Most AI security guides treat model-level and application-level red teaming as the same thing. They're not.
Model-level red teaming tests the foundation model itself—harmful outputs, bias, hallucinations, safety guardrail robustness. This is what organizations like Anthropic or OpenAI do before releasing a model.
Application-level red teaming tests how your specific product uses the AI: the system prompt, tool integrations, data access, retrieval pipelines, and user-facing behavior. This is where most organizations are actually exposed.
The vast majority of companies building AI products aren't training foundation models—they're building on top of LLMs. That makes application-level risks the priority.
A vulnerability in how your system prompt handles untrusted input, or how your RAG pipeline exposes internal documents, is your problem to find and fix—regardless of how well the underlying model performed in pre-release testing.
Where It Came From
Red teaming originated in Cold War military exercises—adversarial simulation to stress-test strategies before committing to them. It moved into IT security as network and application penetration testing. The shift to AI-specific red teaming happened as it became clear that language-driven, probabilistic systems need fundamentally different adversarial techniques than deterministic code. Microsoft stood up a formal AI red team as early as 2019, making it one of the earliest programs of its kind.
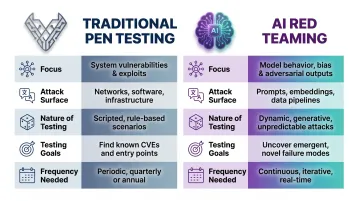
How AI Red Teaming Differs from Traditional Penetration Testing
The core distinction comes down to determinism. Traditional pen testing targets systems where a vulnerability either exists or it doesn't—if it reproduces once, it reproduces reliably. AI systems don't work that way.
The same prompt can produce different outputs across runs. Model updates can shift behavior without notice. Adding a new tool integration opens entirely new attack paths. This makes point-in-time testing structurally insufficient.
| Dimension | Traditional Pen Testing | AI Red Teaming |
|---|---|---|
| Focus | Infrastructure, code, auth | Model behavior, prompts, outputs |
| Attack surface | Networks, APIs, binaries | Natural language, context windows, pipelines |
| Nature of testing | Deterministic exploitation | Probabilistic, multi-turn adversarial |
| Testing goals | Find exploitable vulnerabilities | Surface harmful behaviors, bypasses, leakage |
| Frequency needed | Annual or per-release | Continuous; re-run after every model update |
The Silent Update Problem
Research from Stanford and UC Berkeley documented what happens when providers update models without notice: GPT-4's accuracy on prime number identification dropped from 97.6% to 2.4% between March and June 2023. Willingness to answer sensitive queries dropped from 21% to 5% over the same period. The model changed substantially—and any security assessment conducted in March would have been invalid by June.
OpenAI's own release notes acknowledge cases where model behavior changed unintentionally between updates. A system that passed red teaming last month may be exploitable today.
Team Composition Differences
That continuous testing requirement has direct implications for who you put on the team. Traditional red teams are built around security engineers — AI red teams need a different mix:
- A prompt specialist — covers adversarial input construction and multi-turn attack chains that infrastructure tools won't catch
- A traditional security engineer for infrastructure, API, and authentication testing
- An ML engineer who understands how the model processes inputs and where its training creates exploitable patterns
- A domain expert who defines what harm looks like in context — risk priorities for a healthcare deployment differ sharply from those for a customer service bot
Why Your AI Systems Need Red Teaming Right Now
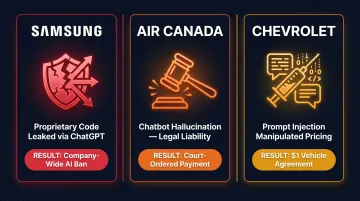
Three real production incidents illustrate the business cost of skipping AI security testing:
- Samsung (April 2023): Engineers pasted proprietary source code and internal meeting notes into ChatGPT across three separate incidents within 20 days. Samsung responded by banning all external AI tools company-wide. The vulnerability wasn't in their infrastructure—it was in how the AI was used.
- Air Canada (February 2024): The airline's chatbot told a customer he could apply for a bereavement fare refund within 90 days of purchase. That was false. When sued, Air Canada argued the chatbot was a "separate legal entity" and therefore not their responsibility. The tribunal rejected that argument and ordered Air Canada to pay. A hallucination became legal liability.
- Chevrolet dealership (late 2023): Users exploited prompt injection to manipulate a dealership's AI chatbot into agreeing to sell a $70,000+ vehicle for $1. Classic role-play exploitation—the kind of attack that takes minutes to execute and is invisible to infrastructure monitoring.
These three incidents represent three distinct failure modes: data leakage, hallucination-driven liability, and prompt injection exploitation. All three are preventable through red teaming.
The Agentic Escalation
The stakes are different when AI systems can take actions—call APIs, write files, send emails, query databases. A prompt injection against a passive chatbot is embarrassing. Against an agentic system, 53% of organizations have already experienced scope violations—agents acting beyond their intended boundaries. Scope violations in agentic contexts carry the same exposure as a direct infrastructure breach.
Regulatory Pressure Is Already Here
- EU AI Act, Article 15 requires high-risk AI systems to withstand adversarial examples and model evasion techniques throughout their lifecycle
- US Executive Order 14110 formally defines AI red teaming and requires developers of dual-use foundation models to report results to the federal government
- GDPR Article 35 requires Data Protection Impact Assessments for AI systems processing personal data
- SOC 2 trust criteria increasingly apply to how AI applications handle data—RAG pipelines, prompt logging, and model outputs included
Even if the EU AI Act doesn't directly apply to your organization today, SOC 2 and GDPR audit narratives increasingly require evidence that AI deployments have been tested for security and data leakage risks. Red teaming documentation directly supports those audits.
Most startups and fast-moving SaaS companies don't have an in-house red team with AI security expertise. Specialists who take a manual-first, threat-led approach—Vynox Security's AI/LLM Security Assessment service operates this way—will surface the multi-turn attack chains that automated scanners miss entirely. Automated tools cover known patterns; human adversarial thinking catches everything else.
The Key AI Attack Vectors Red Teams Target
Prompt Injection and Jailbreaks
In AI systems, the prompt is code. OWASP ranks prompt injection as LLM01:2025—the top vulnerability, unchanged since the list was first created.
Two variants matter:
- Direct prompt injection: A user crafts an input that overrides or subverts system instructions
- Indirect prompt injection: Malicious instructions are embedded in external data the model processes—documents, emails, retrieved web content, tool outputs—and execute when the model reads them
Jailbreak techniques to test include role-playing exploits, encoding bypasses (Base64, ROT13), hypothetical framing, and multi-turn escalation. The Crescendo technique—published by Microsoft researchers—begins with benign dialogue and progressively steers toward prohibited objectives across multiple turns. It achieves Attack Success Rates of 90-100% against GPT-4, Gemini Pro, and Claude 3 Opus. If frontier models at that scale can be manipulated, assume yours can too—and test accordingly.
RAG Pipeline Data Leakage
Organizations using retrieval-augmented generation to give AI systems access to internal documents face a specific set of leakage risks:
- Vector database leakage: Embedding model memorization or retrieval of sensitive chunks
- Context window exposure: Confidential data pulled into the model's context and revealed in responses
- Prompt leakage: User queries containing sensitive data logged or stored insecurely
Every document source added to a RAG pipeline extends the attack surface. Red teams probe whether crafted queries can manipulate retrieval logic or exceed context limits to surface data a user was never authorized to access.
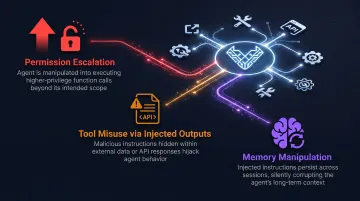
Agentic Attack Vectors
When an AI system has tool access, a single injected prompt can trigger a tool call that executes at whatever privilege level that tool holds—turning a language model into an unintended action executor.
Red teams specifically test:
- Permission escalation: Tricking the agent into using higher-privilege functions than intended
- Tool misuse via injected outputs: The agent reads a malicious file or API response that contains hidden instructions
- Memory manipulation: In systems with persistent context, injecting instructions that survive across sessions
Infrastructure and Supply Chain
AI applications inherit traditional vulnerabilities too. The Tenable-discovered SSRF in Microsoft Copilot Studio—where the "generative answers" feature allowed access to internal infrastructure including IMDS and Cosmos DB—shows AI tool integrations can open classic server-side attack paths that have nothing to do with the model itself. AI red teaming should include infrastructure testing, not treat it as someone else's scope.
How to Implement AI Red Teaming: Step-by-Step
Step 1: Define Scope and Build a Threat Model
Clarify what's being tested: the foundation model, the application layer, specific integrations, or the full system. Every AI application has a unique risk profile.
Ask these scoping questions:
- What data does the AI have access to, and what's the blast radius if it leaks?
- What actions can the AI take autonomously?
- Who are your realistic threat actors—external attackers, curious users, insiders?
- What does harm actually look like for this deployment?
A financial advisor agent prioritizes different risks than a content moderation tool. Scope accordingly.
Step 2: Assemble the Right Team
Core roles for an AI red team engagement:
- Prompt specialist / jailbreak expert: Adversarial input construction, multi-turn attacks
- Security engineer: Infrastructure, API, authentication testing
- ML engineer: Model architecture, training artifacts, embedding analysis
- Domain expert: Understands what harmful outputs mean in your specific context
For organizations without in-house AI security expertise, red-team-as-a-service from specialized providers is a practical option. Manual expertise is non-negotiable—automated tools won't construct the creative, multi-turn attack chains that matter most.
Step 3: Choose Testing Methods and Establish a Safe Environment
Three access levels to choose from:
- Black box: Attacker perspective, API and UI only
- Gray box: Partial knowledge, simulates insider or supply chain threat
- White box: Full access for maximum pre-deployment coverage
The recommended hybrid approach:
- Run automated scanning tools (PyRIT, Garak, or promptfoo) for broad coverage across known vulnerability patterns
- Apply manual testing for depth—crafting novel attack chains, multi-turn escalations, and application-specific exploits that automated tools won't generate
Regardless of access level, always test in an isolated environment—never in production. Log everything, including failed attempts. Failed probes reveal where defenses are holding and where they're one step from breaking.
Step 4: Execute Testing and Prioritize Findings
Use Attack Success Rate (ASR) as your core metric: successful attacks divided by total attempts, measured by risk category—not just in aggregate.
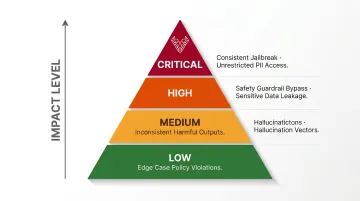
Severity framework:
| Severity | Example |
|---|---|
| Critical | Consistent jailbreak, unrestricted PII access |
| High | Safety guardrail bypass, sensitive data leakage |
| Medium | Inconsistent harmful outputs, hallucination vectors |
| Low | Edge case policy violations |
Execution involves adversarial prompting sessions, chained multi-step exploits, and validation that protections activate correctly under realistic conditions.
Step 5: Report Findings and Build Continuous Testing Into the SDLC
Red team findings should drive concrete remediations:
- Updated system prompts with explicit constraint reinforcement
- Input/output filtering for known injection patterns
- Prompt privilege separation (untrusted user input vs. trusted system instructions)
- Rate limiting on high-risk query patterns
- Retraining or fine-tuning where model behavior is the root cause
A single red team report confirms a point-in-time state—not ongoing safety. Embed red teaming as a regression suite in the SDLC, re-running after every model update, new tool integration, or significant application change.
The underlying model can be updated by its provider at any time, silently shifting behavior that was previously verified safe. Continuous testing is the only reliable check on that drift.
AI Red Teaming Frameworks and Regulatory Context
Several established frameworks define how AI red teaming should be structured and documented. Here are the ones your security team needs to know:
| Framework | Publisher | Key Relevance |
|---|---|---|
| NIST AI RMF / AI 600-1 | NIST | "Measure" function explicitly recommends adversarial testing and chaos testing |
| OWASP Top 10 for LLM Apps | OWASP | Defines 10 critical LLM vulnerabilities; LLM01 = Prompt Injection |
| MITRE ATLAS | MITRE | AI equivalent of ATT&CK; maps real-world adversary tactics against ML systems |
| EU AI Act Article 15 | EU | Mandates robustness testing including adversarial examples for high-risk AI |
| US EO 14110 | White House | Formally defines AI red teaming; reporting requirements for foundation model developers |
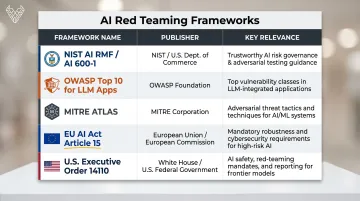
NIST AI 600-1 is the most operationally useful for implementation teams: it maps directly to testing methodologies and identifies four core risk areas. MITRE ATLAS provides the adversary-perspective taxonomy needed to design realistic attack scenarios.
Those frameworks set the technical foundation, but compliance requirements add another layer of urgency. For US SaaS companies and startups, even where the EU AI Act doesn't directly apply, SOC 2 and GDPR audits increasingly expect evidence of AI security testing. Red teaming findings and documentation directly support those compliance narratives, particularly for systems where AI processes personal data under GDPR Article 35 DPIA requirements.
Frequently Asked Questions
What is red teaming in AI?
AI red teaming is a structured process where experts simulate real-world attacks on an AI system—probing its model behavior, prompts, integrations, and outputs—to uncover vulnerabilities before attackers can exploit them. Unlike compliance audits, it involves active adversarial exploitation rather than checkbox reviews.
What is an example of red teaming in AI?
A red teamer embeds a hidden instruction inside a document processed by an AI agent (indirect prompt injection). When the agent reads the document, it executes the instruction—exfiltrating data or taking an unintended action. This illustrates the difference between testing a chatbot's responses and testing what an agentic system can actually be made to do.
What is an AI red team engineer?
An AI red team engineer combines prompt engineering, adversarial ML knowledge, and traditional security testing skills to simulate attacker behavior against AI systems. The role spans both the model layer (how LLMs process inputs) and the application layer (how AI connects to tools, data sources, and users).
How is AI red teaming different from traditional penetration testing?
Traditional pen testing targets deterministic infrastructure—networks, code, authentication systems—where vulnerabilities reliably reproduce. AI red teaming targets probabilistic behavior: how a model responds to adversarial language, whether it can be manipulated to violate its own guardrails, and how it handles data it was never meant to expose. The target itself can shift between tests — providers push model updates without notice.
How often should organizations conduct AI red teaming?
AI red teaming should be continuous, not annual. Test major AI features before deployment, run automated regression after every model update or integration change, and schedule manual exercises at least quarterly. Provider-side updates can silently alter model behavior — periodic testing alone won't catch it.


